Audio: Mit KI zm 3D-Sound (Teil 1)
KI erobert immer mehr Anwendungsgebiete, auch im privaten IT-Bereich. Ich verwende KI-Programme für die Aufbereitung alter Bilder (z.T. mit sehr schlechter Qualität) und für alte private Filme, noch gedreht im Super 8-Format. Nun tut sich ein ganz neues Anwendungsfenster auf, mit nahezu unbegrenztem Gestaltungsspielraum, nämlich das Auseinandernehmen einer normalen Audioaufnahme in Tonspuren der Einzelinstrumente und Sänger. Dies bietet danach die Möglichkeit diese Tonspuren wieder als 3D-Song zusammenzusetzen.
In den Medien wird oft behauptet, dass 3D-Audio, keine Zukunft hat. Ich bin aber der Meinung, mit einen guten AV-Receiver/-Prozessor und sehr guten Boxen schon. Einen 3D-Sound über Kopfhörer sehe ich eher kritisch, aufgrund meiner Erfahrungen mit Apple's Airpods Max sowie Airpods 3 und das 3D-Musikangebot bei Apple Music.
Als Referenzen von guten AV-Receivern/-Prozessoren, sind hier die Geräte von StormAudio zu nennen. Die Einstellmöglichkeiten bei diesen Geräten sind sehr manigfaltig. Sie sind leider recht teuer.
Eine Preisklasse niedriger sind einige AV-Receiver/-Prozessoren der Serie SYNTHESIS von JBL.
Beide Produktklassen haben einen Dante-Interface, was für die Musikproduktion wichtig ist. Jeder Kanal kann von einem Musikprogramm (z.B. mit Nuendo von Steinberg) zur Ausgabe verwendet werden.
Zur reinen Musikwiedergabe von Dolby Atmos- bzw. Auro-3D-Songs reicht aber auch bei einer Minimallautsprecherkonfiguration 5.1.4 ein vergleichbarer AV-Receiver 7015 von Marantz oder x4700h von Denon.
Mit einem sehr guten In-Ear-Kopfhörer (z.B. FH5s Pro von FiiO oder IE 900 von Sennheiser) wird der ganze Schädel zum Konzertsaal, wobei man aber den Stereo-Sound mit hoher Sample-Rate abspielen muss. Nicht jeder erträgt diesen Sound über längere Zeit.
Auch der Sound über einen ausgewiesenen Surround-Kopfhörer wie der JVC XP-EXT1 kommt nicht an den Lautsprechersound einer AV-Anlage heran. Wird aber die Prozessoreinheit vom JVC XP-EXT1 über HDMI an eine NVIDIA-Grafikkarte angeschlossen, NVIDIA High Defintion Audio als Ausgabegerät verwendet und noch der Raumklang auf Dolby Atmos for Home Theater aktiviert, so ist der Raumklang schon recht gut, aber nur, wenn die Audiodateien für 7.1- oder Dolby-Atmos-Surround erstellt wurden. Dazu ist Dolby Access aus dem Microsoft-Store zu installieren. Die Audiodateien sind dann mit den normalen Windows-Media-Player abspielbar.
Um die Masse der existierenden Songs in 3D-Sound umzusetzen, ist der Aufwand für die Musikindustrie sicherlich zu groß. Seltene LP-Pressungen werden sicherlich nie neu bearbeitet, da damit kein Geld verdient werden kann. Bis einmal meine Lieblingssongs offiziell in 3D-Sound vorliegen, werde ich wohl nicht mehr erleben, da ich schon etwas älter bin. Aber mit der heutigen Technik und Software kann jeder selbst tätig werden, um seine Lieblingssongs auf seine Surround-Anlage zu bringen. Man benötigt einen guten Rechner mit einer NVIDIA-Grafikkarte mit CUDA 11.0 und die beiden Programme DeepRemix sowie Audacity. DeepRemix kostet 85€ und Audicity ist frei verfügbar. DeepRemix zerlegt einen Song in Einzelspuren.
Im Apple-Store für den Mac gibt es das Programm Neural Mix Pro, was ähnlich wie DeepRemix arbeitet. Es arbeitet schneller als DeepRemix, aber die Qualität der extrahierten Spuren ist schlechter.
Mit Audacity setzt man einen Song so zusammen, wie es für die eigene AV-Anlage benötigt wird. Als Audio-Zielformat ist FLAC 5.1 zu empfehlen. Auch der persönliche Geschmack kann hier berücksichtigt werden. Ich mag es z.B. nicht, wenn aus den hinteren Lautsprechern das Schlagzeug oder andere Rhythmusgeräte zu hören sind. Der Workflow zur Umsetzung eines Stereo-Songs hin zu einem 3D-Song ist einfach und schnell umgesetzt. Es ist reines Handwerk und erfordert keine großen Kenntnisse.
Wer wirklich seinen Lieblingssong als 3D-Sound in Dolby Atmos will, muss sehr viel mehr Arbeit investieren. Die Spuren aus DeepRemix lassen sich mit der neusten Version von Apple's Logic Pro sehr gut zu einen Dolby Atmos-Sound verarbeiten. Das bevorzugte 3D-Audioobjekt (z.B. eine Stimme, Gitare oder Saxophone) ist aber vorab mit DeepAudio manuell zu extrahieren.
Ich selber bevorzuge Auro-3D mit einer 5.1.4-Lautsprecherkonfiguration, da die Umsetzung hin zum 3D-Sound einfacher ist. Alle umgesetzten Sounds sind in 5.1-FLAC-Dateien zu speichern. Der Rest erledigt die Auro-Matic. Auch lassen sich so die Sounds über eine normale 5.1-Surround-Anlage abspielen. Das Klangerlebnis ist gleichermaßen fantastisch gut. Hier eine Beschreibung von Auro-3D als PDF-Datei.
Sollte die eigene Surround-Anlage keine 5.1-FLAC-Dateien abspielen können (z.B. bei SONOS), so ist das Zielformat zu ändern, z.B. nach Dolby Digital (AC3 mit 48kHz Sample-Rate!).
Wichtiger Hinweis:
Wie bei allen Systemen, die versuchen aus einem Song nachträglich die Einzelspuren zu extrahieren, werden auch hier Tonartefakte mit generiert, die im Gesamtklangbild nicht hörbar sind. Betrachtet man aber eine der neu erzeugten Tonspuren, wirken sie trotzdem störend.
Das hier beschriebene Verfahren hat aber gegenüber der reinen Auromatik den Vorteil, dass man mit den interaktiven Songeditor DeepAudio diese Artefakte sichtbar und gezielt löschen oder editieren kann. So erhält man ein äußerst klares Klangbild der Einzelspuren.
Mein Workflow
Meine Hardware zur Umsetzung der Stereo-Songs nach 5.1-Surround:
- CPU: AMD 5800 X3D
- Grafikkarte: NVIDIA RTX A4000 mit 16GB GDDR6
- 64 GB DDR4-RAM (3600MHz)
Wichtige Voreinstellung in AUDACITY:
Bearbeiten->Einstellungen...->Import/Export -> Erweiterte Misch-Optionen verwenden, damit der Song im FLAC-Format abgespeichert werden kann.
Den Sound als unkomprimierte WAV-Datei sichern. Danach mit AUDACITY normalisieren (Effekt->Normalisieren...) und die Tag's für Künstler und Titel einfügen.
Nun mit DeepRemix die WAV-Datei in 4 Einzel-WAV-Dateien zerlegen, d.h. bei einer WAV-Datei XYZ.wav erhält man 4 weitere WAV-Dateien:
- XYZ_Bass.wav,
- XYZ_Drums.wav,
- XYZ_Other.wav und
- XYZ_Vocals.wav.
Um nun einen 5.1-Surround in einer FLAC-Datei zu erhalten, sind 6 Spuren in AUDACITY zu erstellen. Dies kann einfach durch Drag/Drop aus dem Datei-Explorer geschehen:
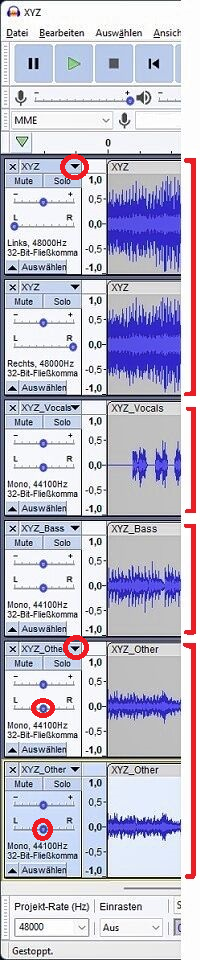
Spur 1: Drag/Drop der normalisierten originalen Stereo-WAV-Datei XYZ.wav nach AUDACITY. Trennen der Spuren in linken und rechten Kanal. Dazu Pulldown-Menü der Spur: Stereospur aufteilen.
Spur 2: Liegt nach Aufteilung der Stereospur vor.
Spur 3: Drag/Drop von XYZ_Vocals.wav nach AUDACITY. Danach auf Mono heruntermischen, dazu Kopfmenü: Spuren->Mix->Stereo zu Mono heruntermischen.
Spur 4: Drag/Drop von XYZ_Bass.wav nach AUDACITY. Danach auf Mono heruntermischen, dazu Kopfmenü: Spuren->Mix->Stereo zu Mono heruntermischen.
Spur 5: Drag/Drop von XYZ_Other.wav nach AUDACITY. Trennen der Spuren in linken und rechten Kanal.
Pulldown-Menü der Spur: Stereospur aufteilen.
Spur 6: Liegt nach Aufteilung der Stereospur vor.
Am Schluss den Menüpunkt Datei->Exportieren->Audio exportieren... auswählen und als FLAC-Datei exportieren. Bei einigen Abspielkonfigurationen (JVC XP-EXT1-Kopfhörer, SONY HT-A9, alle Soundbars) empfehlen sich 7.1-FLAC-Dateien. Dazu sind einfach die letzten beiden Spuren zu kopieren.
Das Ergebnis ist umso besser, je höher die Abtastrate der Originaldatei ist. Songs mit einer höheren Abtastraten, sollten bis auf die Normalisierung vor der Verarbeitung mit DeepRemix nicht verändert werden. Evtl. kann es Probleme beim Abspielen von FLAC-5.1-Dateien geben, die eine 196kHz-Abtastrate verwenden. Hier kann ein Abspeichern mit einer 96kHz-Abtastrate helfen. Bei mir kann die Abspielkonfiguration, bestehend aus UHD-Player, AV-Receiver und Verkabelung, keine FLAC-Dateien mit 192kHz-Abtastrate abspielen, so dass ich diese FLAC-Dateien mit 96kHz abspeichere.
Copyright © 12.12.2021 (Update: 18.07.2022) hadv.de. All Rights Reserved.